


Microsoft Research: What is UniversalNER?
Targeted Distillation from Large Language Models for Open Named Entity Recognition


Hello Everyone,
In this Newsletter I’m going to from now on be covering A.I. papers (with infographics) that come across my desk in a brief sort of overview. I hope it’s helpful reading to some of you and they are just snippets.
Sheng Zang wrote:
Imitation models like Alpaca & Vicuna are good at following instructions but lag behind ChatGPT in NLP benchmarks. Introducing UniversalNER: a small model trained with targeted distillation, recognizing 13k+ entity types & outperforming ChatGPT by 9% F1 on 43 datasets!
Links from his LinkedIn Post here.
Dataset & model: https://lnkd.in/gStQm8pa
Project page & demo: https://lnkd.in/g8cKe_cy
Paper: https://lnkd.in/gVpsCh-c
Large language models (LLMs) have demonstrated remarkable generalizability, such as understanding arbitrary entities and relations. Instruction tuning has proven effective for distilling LLMs into more cost-efficient models such as Alpaca and Vicuna.
Yet such student models still trail the original LLMs by large margins in downstream applications. In this paper, we explore targeted distillation with mission-focused instruction tuning to train student models that can excel in a broad application class such as open information extraction.
Using named entity recognition (NER) for case study, we show how ChatGPT can be distilled into much smaller UniversalNER models for open NER. For evaluation, we assemble the largest NER benchmark to date, comprising 43 datasets across 9 diverse domains such as biomedicine, programming, social media, law, finance.
Without using any direct supervision, UniversalNER attains remarkable NER accuracy across tens of thousands of entity types, outperforming general instruction-tuned models such as Alpaca and Vicuna by over 30 absolute F1 points in average. With a tiny fraction of parameters, UniversalNER not only acquires ChatGPT's capability in recognizing arbitrary entity types, but also outperforms its NER accuracy by 7-9 absolute F1 points in average.
Remarkably, UniversalNER even outperforms by a large margin state-of-the-art multi-task instruction-tuned systems such as InstructUIE, which uses supervised NER examples. We also conduct thorough ablation studies to assess the impact of various components in our distillation approach. We will release the distillation recipe, data, and UniversalNER models to facilitate future research on targeted distillation.
GitHub
https://github.com/universal-ner/universal-ner (they will release the code before August 13th, 2023 they say).
Hugging Face
https://huggingface.co/Universal-NER
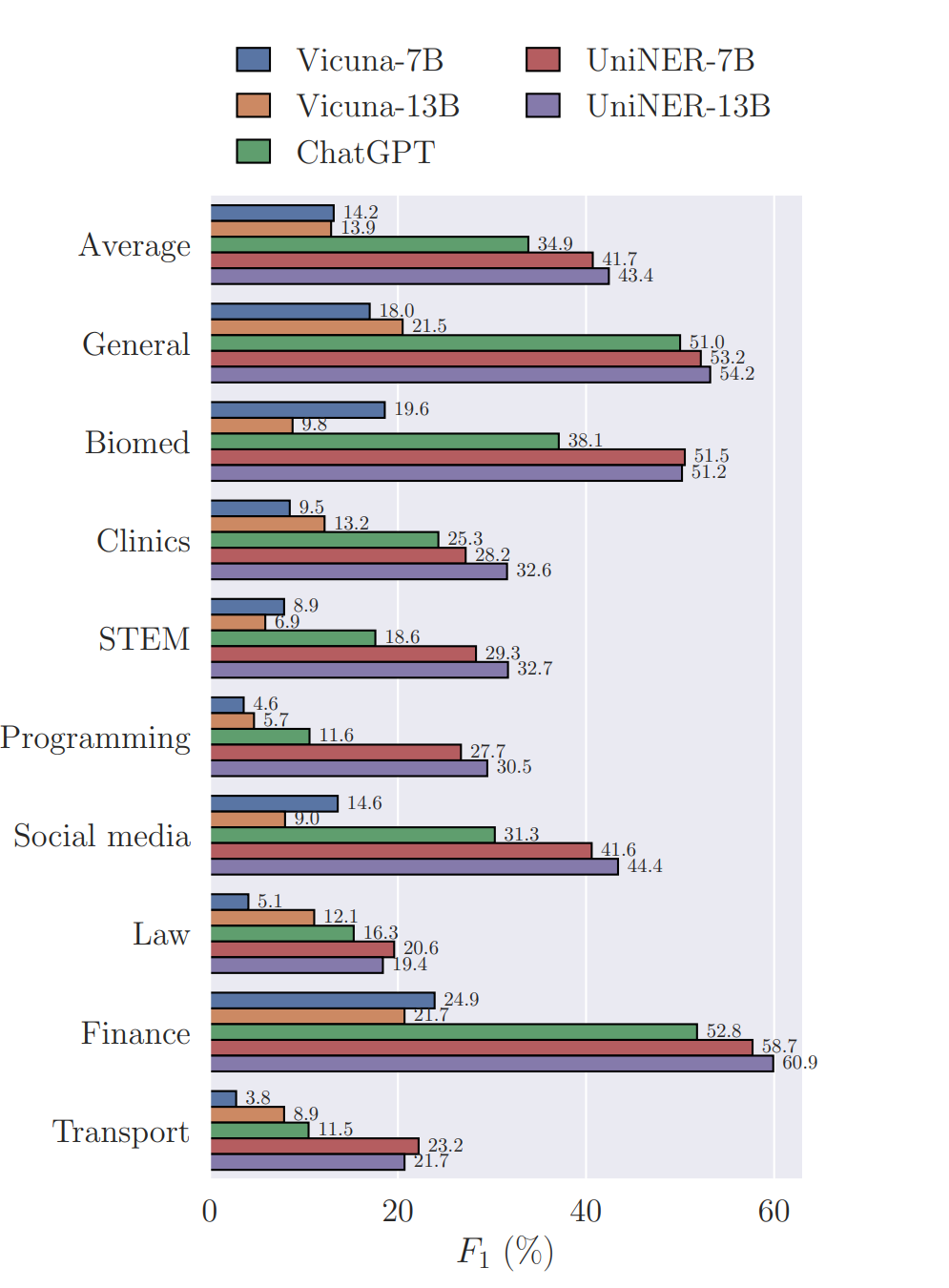
The performance is kind of impressive:

Joint work with Wenxuan Zhou, Yu Gu, Muhao Chen, Hoifung Poon
We propose a general recipe for targeted distilling where we train student models using mission-focused instruction tuning for a broad application class such as open information extraction. We show that this can maximally replicate LLM’s capabilities for the given application class, while preserving its generalizability across semantic types and domains. Using NER as a case study, we successfully distill these capabilities from LLMs into a much smaller model UniversalNER that can recognize diverse types of entities or concepts in text corpora from a wide range of domains. UniversalNER surpasses existing instruction-tuned models at the same size (e.g., Alpaca, Vicuna) by a large margin, and shows substantially better performance to ChatGPT.
Performance

Universal NER Benchmark -- the largest NER benchmark to date

Benchmark: The Universal NER benchmark encompasses 43 NER datasets across 9 domains, including general, biomedical, clinical, STEM, programming, social media, law, finance, and transportation domains. An overview of the data distribution is shown below.
Zero-shot Performance: UniversalNER surpasses existing instruction-tuned models at the same size (e.g., Vicuna) by a large margin. More importantly, UniversalNER outperform ChatGPT in terms of average F1. This demonstrates that our proposed targeted distillation from diverse inputs yields models that have superior performance on a broad application class while maintaining a relatively small model size. Domain breakdowns also show the improvements of UniversalNER over ChatGPT.
Thanks for reading!